# 2.1 C 语言版本 TODO
TODO: 标准介绍,各标准特性
C 语言规范的最大的变化则发生在 C99 规范之中。其后的 C11 虽然也有一些特性,但更多的算是为了与 C++ 同步而引入的新特性。
# 2.1.1 C 99
- 增加了对编译器的限制,比如源始码每行要求至少支持到 4095 字节,变量名函数名的要求支持到 63 字节(extern 要求支持到 31)。
- 增强了预处理功能。例如:
- 宏支持取可变参数
#define Macro(...) __VA_ARGS__。// ##args 表示允许变参部分为空。 #define debug(fmt, ...args) \ printf("[DEBUG]: " fmt, ##args); #define debug(fmt, ...) \ printf(fmt, ##__VA_ARGS__) // # 表示将参数字符串化 #define str(i) #i // 空格可以连接字符串 #define strcat(str1, str2) str1 str2 // ## 还可以用来将两个 token 连接成一个 token #define link(a,b) a##b // link(3,5) -> 351
2
3
4
5
6
7
8
9
10
11
12 - 使用宏的时候,允许省略参数,被省略的参数会被扩展成空串。
- 支持//开头的单行注释(这个特性实际上在C89的很多编译器上已经被支持了)
- 宏支持取可变参数
- 增加了新关键字
restrict,inline,_Complex,_Imaginary,_Bool,restrict 修饰指针,防止未定义的行为,像编译器保证,某个指针指向的空间,只能从该指针访问。- 支持
long long,long double _Complex,float _Complex等类型
- 支持
- 支持不定长的数组,即数组长度可以在运行时决定,比如利用变量作为数组长度。声明时使用
int a[var]的形式。不过考虑到效率和实现,不定长数组不能用在全局,或 struct 与 union 。 - 变量声明不必放在语句块的开头,for语句提倡写成for(int i=0;i<100;++i) 的形式,即i只在for语句块内部有效。
- 允许采用
type-name{xx,xx,xx}这样类似C++的构造函数的形式构造匿名的结构体,即复合文字特性。如(int[]){1,3},(int){1},复合字面量是匿名的,所以不能先创建然后再使用它,必须在创建的同时使用它。Compound Literals - 初始化结构体的时候允许对特定的元素赋值,形式为:
struct test{int a[3],b;} foo[] = { [0].a = {1}, [1].a = 2 };struct test{int a, b, c, d;} foo = { .a = 1, .c = 3, 4, .b = 5 }; // 3,4 是对 .c,.d 赋值的
- 格式化字符串中,利用
\u支持 unicode 的字符。 - 支持 16 进制的浮点数的描述。
- printf, scanf 的格式化串增加了对 long long int 类型的支持。
- 浮点数的内部数据描述支持了新标准,可以使用 #pragma 编译器指令指定。
- 除了已有的
__LINE__和__FILE__以外,增加了__func__得到当前的函数名。 - 允许编译器化简非常数的表达式。
- 修改了
/和%处理负数时的定义,这样可以给出明确的结果,例如在C89中-22 / 7 = -3, -22 % 7 = -1,也可以-22 / 7= -4, -22 % 7 = 6。 而C99中明确为 -22 / 7 = -3, -22 % 7 = -1,只有一种结果。 - 取消了函数返回类型默认为 int 的规定。
- 允许在 struct 的最后定义的数组不指定其长度,写做
[](flexible array member)柔性数组。 - const const int i 将被当作 const int i 处理。
- 增加和修改了一些标准头文件,比如定义 bool 的
<stdbool.h>,定义一些标准长度的int的<inttypes.h>,定义复数的<complex.h>,定义宽字符的<wctype.h>,类似于泛型的数学函数<tgmath.h>,浮点数相关的<fenv.h>。在<stdarg.h>增加了va_copy用于复制...的参数。<time.h>里增加了struct tmx,对struct tm做了扩展。 - 输入输出对宽字符以及长整数等做了相应的支持。
#include <locale.h>
#include <stdio.h>
#include <stdlib.h>
#include <wchar.h>
int main(int argc, char* argv[]) {
setlocale(LC_ALL, ""); // 本地化设置
char* str = "宽字符测试";
wchar_t* wstr = L"宽字符测试";
printf("%s\n", str); // 输出单(多)字节字符串
wprintf(L"%ls\n", wstr); // 输出宽字符串
getchar();
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 2.1.2 C11 & GNU C
过时弃用
gets()。
新语言特性
- 多线程环境(原子对象
_Atomic,线程本地存储_Thread_local) - 增强的对齐支持(对齐方式查询
_Alignof,对齐方式加强_Alignas,过对齐类型Over-aligned types),用于指定和查询特定对齐方式的类型。(stdalign.h) - Unicode 支持。(
u/U字符常量,u8/u/U字符串字面量)。(uchar.h) - 泛型选择表达式(
_Generic)。 - 无返回值函数。(
_Noreturn) - 匿名结构体和枚举成员(允许在结构体和联合体中定义匿名的成员,这些成员在定义时不指定名称。)。
- Fine-grained evaluation order(细粒度求值顺序)。
- 延长临时对象的生存期。
_Static_assert,静态断言,用于在编译时进行静态断言检查。- 可分析性,限制某些未定义行为潜在执行结果,提升程序的静态语法分析结果。
- 新的 fopen() 模式,(“…x”)。类似 POSIX 中的 O_CREAT|O_EXCL,在文件锁中比较常用。
- 新增 quick_exit() 函数作为第三种终止程序的方式。当 exit()失败时可以做最少的清理工作。
- 删除 gets(),改为 gets_s(),可用 fgets() 替代。
- 新增安全函数(safe functions)家族,如 gets_s,printf_s 和 scanf_s,strcpy_s 和 strcat_s,memcpy_s 和 memmove_s,但并不是标准 C 语言库函数。
可选特性的功能测试宏
__STDC_ANALYZABLE__指示支持可分析性。__STDC_LIB_EXT1__指示支持边界检查函数。__STDC_NO_ATOMICS__指示不支持原子对象与原子操作库。__STDC_NO_COMPLEX__指示不支持复数类型与复数数学函数。这些特性在 C99 中为强制。__STDC_NO_THREADS__指示不支持线程局部存储与线程支持库。__STDC_NO_VLA__指示不支持非常量长度数组与可变修改类型。这些特性在 C99 中为强制。
库特性
新头文件:
<stdalign.h>
<stdatomic.h>
<stdnoreturn.h>
<threads.h>
<uchar.H>
2
3
4
5
并发支持库(
threads.h)_Noreturn 关键字:引入了 _Noreturn 关键字,用于指示函数不会返回。
泛型宏_Generic 关键字:引入了 _Generic 关键字,用于实现基于类型的泛型编程。
Unicode 支持:C11 增强了对 Unicode 字符和字符串的支持,包括 Unicode 转义序列和宽字符字符串常量。
对函数指针的限制放宽:C11 放宽了对函数指针的限制,允许将函数指针转换为其他类型的指针,并且允许将函数指针转换为 void* 类型的指针。
新的库函数:C11 引入了一些新的标准库函数,包括对泛型编程的支持函数 tgmath.h、字符串安全版本的库函数 strlcpy()、strlcat() 等。
_Noreturn 使用:
使用 _Noreturn 关键字的目的是帮助编译器进行更好的优化,因为它提供了关于函数行为的额外信息。编译器可以在知道函数不会返回时进行一些优化,例如消除不可达代码或生成更高效的代码。
_Noreturn 并非强制性的,它只是一种提示。编译器不会强制要求函数永远不会返回,但是如果函数实际上返回了,编译器可能会发出警告。
#include <stdbool.h>
#include <stdlib.h>
extern _Noreturn void test();
int main(int argc, const char* argv[])
{
test();
return 0;
}
_Noreturn void test()
{
while (true);
}
#include <stdnoreturn.h>
noreturn void func()
{
quick_exit(EXIT_SUCCESS);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
_Generic :
语法规则:_Generic(expression, type1: result1, type2: result2, ..., default: result_default)
_Generic 表达式的求值规则如下:
对于给定的 expression,首先根据 type1、type2 等类型标签的顺序,找到与 expression 类型匹配的第一个类型标签。
如果找到了匹配的类型标签,则返回对应的结果表达式。
如果没有找到匹配的类型标签,则返回默认结果表达式。
sample:
#include <stdio.h>
#define print_type(x) _Generic((x), \
int: printf("Type: int\n"), \
float: printf("Type: float\n"), \
double: printf("Type: double\n"), \
default: printf("Unknown type\n"))
int main() {
int a = 10;
float b = 3.14;
char c = 'A';
print_type(a); // Type: int
print_type(b); // Type: float
print_type(c); // Unknown type
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
static_assert 宏:
_Static_assert 关键字和 static_assert 宏均在编译时测试软件断言。 它们可用于全局或函数范围。
相反,assert 宏、_assert 和 _wassert 函数在运行时测试软件断言,并产生运行时成本。
// requires /std:c11 or higher
#include <assert.h>
enum Items
{
A,
B,
C,
LENGTH
};
int main()
{
// _Static_assert is a C11 keyword
_Static_assert(LENGTH == 3, "Expected Items enum to have three elements");
// Preferred: static_assert maps to _Static_assert and is compatible with C++
static_assert(sizeof(int) == 4, "Expecting 32 bit integers");
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
GNU C case 范围
支持:
case low ... high
case 'A' ... 'Z'
2
例:
switch (name) {
case '0' ... '7':
val = 9 + name - '0';
break;
case '8' ... '9':
val = 3 + name - '0';
break;
default:
return val;
}
2
3
4
5
6
7
8
9
10
注意:... 两边要用空格,否则会出错。
GNU C typeof
例子:
#define max(a,b) ({\
typeof(a) _a = (a);\
typeof(b) _b = (b);\
(void) (&_a == &_b);\
_a > _b ? _a : _b;})
2
3
4
5
(void) (&_a == &_b) 判断两个数类型是否相同,如果不同,会抛出警告。
标号初始化
GNU C 语言可以通过指定索引或结构体成员名来初始化,不必按照原来固定的顺序来进行初始化。
例子:
static const struct file_operations zero_fops = {
.open = my_open
.read = my_read
}
2
3
4
这种初始化方法能保证已知元素的正确性,对于未初始化成员的值为 0 或者为 NULL。
# 2.2 编译过程
gcc x.c 默认的产物是 a.out,assembler output 的缩写。
# 2.2.1 预处理
调用预处理器cpp,完成宏展开、头文件包含、处理条件编译、删除注释等工作。
预处理指令
#error error message,#error预处理指令的作用是,编译程序时,只要遇到#error 就会生成一个编译错误提示消息,并停止编译。#warning warning message。(c23)#define#elif#elseendifififdefifndefimport(C++),过去一直合并类型库中的信息。 类型库的内容将转换为 C++ 类,主要描述 COM 接口。includelinepragmaundefusing(C++),将元数据导入使用/clr编译的程序。
例子:
#ifdef __STDC_NO_ATOMICS__
#error "不支持 C11 原子操作!"
#endif
#include <stdlib.h>
#include <stdbool.h>
#include <inttypes.h>
#include <threads.h>
#include <stdio.h>
#define add(a,b) a+b
int main(int argc, const char* argv[])
{
int a = 0;
#if a == 0
printf("1, a = %d\n", a);
#elif a == 2
printf("3, a == %d\n", a);
#else
printf("2, a != %d\n", a);
#endif
printf("%d\n", add(1,3));
#undef add
return EXIT_SUCCESS;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
一些预定义的宏:
__DATE__ 进行预处理的日期(“Mmm dd yyyy”形式的字符串文字,如May 27 2006)
__FILE__ 代表当前源代码文件名的字符串文字 ,包含了详细路径,如 G:/program/study/c+/test1.c
__LINE__ 代表当前源代码中的行号的整数常量
__TIME__ 源文件编译时间,格式微“hh:mm:ss”,如:09:11:10;
__FUNCTION__ 当前所在函数名
gcc -E -o a.i a.c
# 2.2.2 编译
调用编译器 cc1,把源程序翻译成目标系统的汇编文件 .s。
将预处理得到的程序代码,经过一系列的词法分析、语法分析、语义分析以及优化,加工为当前机器支持的汇编代码。
gcc -S -o a.s a.i
# 2.2.3 汇编
调用汇编器 as,将汇编指令翻译成机器指令,生成可重定位目标文件。
gcc -o a.o -c a.s
# 2.2.4 链接
调用链接器 ld ,将生成的可重定位文件与相关库文件链接,生成可执行目标文件。
- 符号分析
- 重定位。(重新分配地址)
gcc -o a a.o -lm
# 2.3 宏
避免使用宏,尽量使用编译器而不用预处理。
多行的宏,需要用下面的结构包围起来:
do{
}while(0)
2
3
c99 的变参宏
宏可以接受可变数目的参数,主要用于在输出函数里,例:
#define pr_debug(fmt, ...)\
dynamic_pr_debug(fmt, ##__VA_ARGS__)
#define kdebug(fmt,args...) printf (COLOR_BLUE fmt COLOR_NONE,##args)
2
3
4
__VA_ARGS__ 是编译器保留字段,预处理时把参数传递给宏。
## 可用于连接字符串。
# 2.4 字符串
不要将字符串常量用于非 const 的字符串变量。
字符串常量是 const char* 类型。
字符数组可以看作 char* const 类型,数组名执行地址不可变,但可以通过指针修改字符串。
# 2.5 内存映像
CPU是计算机的核心,决定了计算机的数据处理能力和寻址能力。CPU一个时钟,也就是一次能处理的数据的大小由寄存器的位数和数据总线的宽度决定,通常所说的CPU的32位、64位可以理解为寄存器的位数,也可以理解为数据总线的宽度。
以32位CPU为例子,即一次能处理32Bit,即4个字节的数据。典型的32位处理器是Intel 80386,它的数据总线宽度有32位,地址总线宽度也是32位,寻址能力为232 = 4GB
数据总线用于在CPU和内存之间传输数据,地址总线用于在内存上定位数据,地址总线的宽度往往随着数据总线的宽度增大而增大,以访问更大的内存。
同时CPU支持的物理内存只是理论上的数据,实际应用中会受到操作系统的限制,比如说win7 64位家庭版最大支支持8GB和16GB的物理内存,win7 64位专业版可以支持到192GB的物理内存。但是32位CPU寻址能力没有这么大,所以要通过两次寻址来实现。
所谓的虚拟空间,就是程序可以使用的虚拟地址的有效范围。虚拟地址和物理地址的映射关系由操作系统决定,相应地,虚拟地址空间的大小也由操作系统决定,但还会受到编译模式的影响。
windows和Linux都会对虚拟地址进行了限制,仅使用虚拟地址的低48位(6个字节),总的虚拟空间大小位为248=256TB,而且任何虚拟地址的48位至63位必须与47位一致。
如果内存大于物理内存,或者内存中剩余的空间不够容纳当前的程序,那么操作系统会将内存中用不到的一部分数据写入磁盘,等需要的时候再读取回来。程序只管使用4GB的内存,而不用关心硬件资源。
32位内存映像如下:
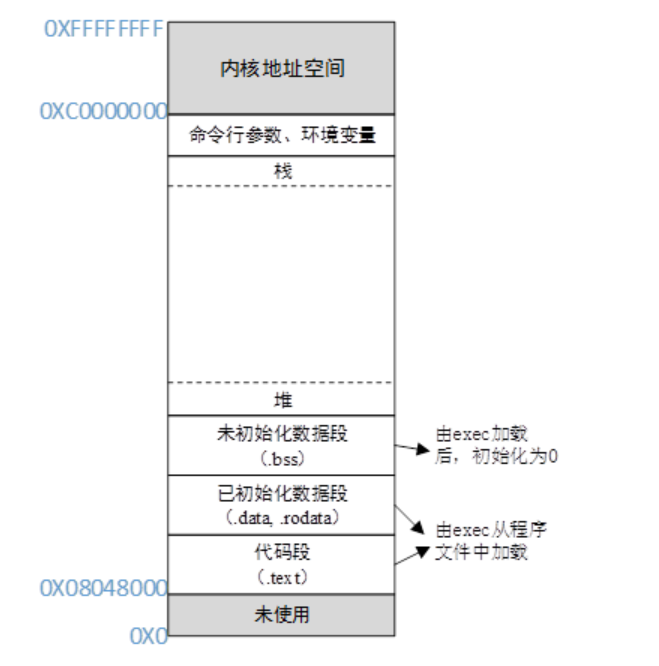
ulimit -s 查看栈空间大小,单位 Mb。
c语言五大内存分区
- 栈区(stack):存放函数形参和局部变量(auto类型),由编译器自动分配和释放(
.stack) - 堆区(heap):该区由程序员申请后使用,需要手动释放否则会造成内存泄漏。如果程序员没有手动释放,那么程序结束时可能由 OS 回收。(
.heap) - 全局/静态存储区:存放全局变量和静态变量(包括静态全局变量与静态局部变量),未初始化的全局变量和静态变量放在一块(
.bss),初始化的放在另一块(.data),编译时就分配好了。 - 常量区:只读数据段:常量在统一运行被创建,常量区的内存是只读的,程序结束后由系统释放。(
.rodata)程序代码段:存放程序的二进制代码,内存由系统管理(.text)
其中rodata区和text区在加载时会合并到一个段中,该段称为常量区,该区域的内容只允许读,不允许修改。
data 区和bss区在加载时合并到一个段中,该段被称为全局区。
bss 段(未手动初始化的数据)并不给该段的数据分配空间,只是记录数据所需空间的大小。 data段(已手动初始化的数据)为数据分配空间,数据保存在目标文件中。
data 段包含经过初始化的全局变量以及它们的值。
bss 段的大小从可执行文件中得到,然后链接器得到这个大小的内存块,紧跟在数据段后面。当这个内存区进入程序的地址空间后全部清零,包含data和bss段的整个区段此时通常称为数据区。
.bss是不占用可执行文件空间的,只占用运行时空间,其内容由操作系统初始化(清零),初始化为 0 的全局变量出于编译优化的策略还是被保存到 bss 段,可通过 nm 命令查看。
rodata
用 const 修饰的全局变量放在 rodata 里(mm 查看后,可看到是在 R 区),不可以取地址修改,字符串默认就是常量。
rodata的意义同样明显,ro代表read only,即只读数据(const)。关于rodata类型的数据,要注意以下几点:
- 常量不一定就放在rodata里,有的立即数直接编码在指令里,存放在代码段(.text)中。
- 对于字符串常量,编译器会自动去掉重复的字符串,保证一个字符串在一个可执行文件(EXE/SO)中只存在一份拷贝。
- rodata是在多个进程间是共享的,这可以提高空间利用率。
- 在有的嵌入式系统中,rodata放在ROM(如norflash)里,运行时直接读取ROM内存,无需要加载到RAM内存中。
- 在嵌入式linux系统中,通过一种叫作XIP(就地执行)的技术,也可以直接读取,而无需要加载到RAM内存中。由此可见,把在运行过程中不会改变的数据设为rodata类型的,是有很多好处的:在多个进程间共享,可以大大提高空间利用率,甚至不占用RAM空间。同时由于rodata在只读的内存页面(page)中,是受保护的,任何试图对它的修改都会被及时发现,这可以帮助提高程序的稳定性。
在64位环境下,虚拟地址空间大小为 256TB,Linux 将高 128TB 的空间分配给内核使用,而将低 128TB 的空间分配给用户程序使用。
64位内存空间分布情况如下:
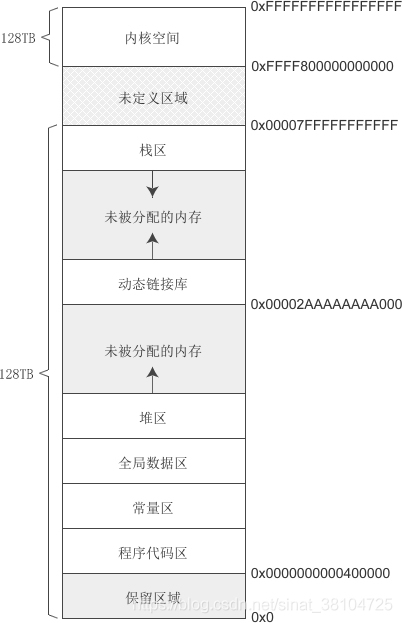
注意:
栈一般的增长方向是:高地址向低地址。
堆增长方向是:低地址向高地址。
这个上下文里说的“栈”是函数调用栈,是以“栈帧”(stack frame)为单位的。每一次函数调用会在栈上分配一个新的栈帧,在这次函数调用结束时释放其空间。
被调用函数(callee)的栈帧相对调用函数(caller)的栈帧的位置反映了栈的增长方向:如果被调用函数的栈帧比调用函数的在更低的地址,那么栈就是向下增长;反之则是向上增长。而在一个栈帧内,
局部变量是如何分布到栈帧里的(所谓栈帧布局,stack frame layout),这完全是编译器的自由。
至于数组元素与栈的增长方向:C与C++语言规范都规定了数组元素是分布在连续递增的地址上的。
每个函数都是一个栈帧,栈的分配是按着这个来的,而栈帧里是怎么分配完全看编译器来。
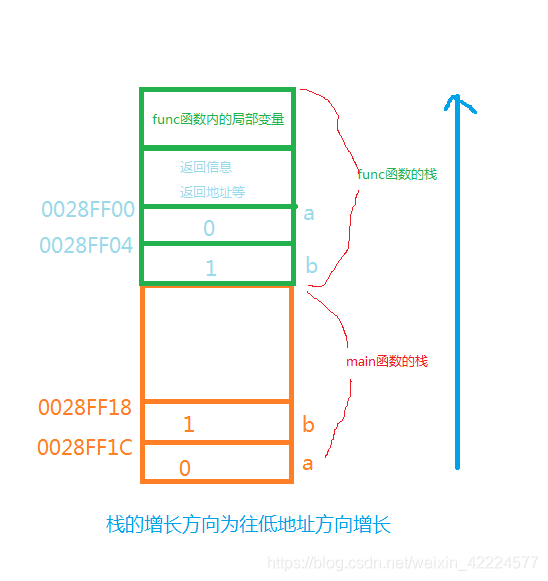
内核空间(1G,0xc0000000 ~ 0xffffffff)
用户空间(3G, 0x00000000 ~ 0xC0000000)
当进程/线程运行在内核空间时就处于内核态,而进程/线程运行在用户空间时则处于用户态。
// 递归函数
#include <stdio.h>
void recursive_function(int depth)
{
int local_variable;
if (depth > 0) {
recursive_function(depth - 1);
}
printf("Address of the local variable: %p\n", &local_variable);
}
int main()
{
recursive_function(5);
return 0;
}
// 输出:
// Address of the local variable: 00000041619ffa0c // 栈顶
// Address of the local variable: 00000041619ffa4c
// Address of the local variable: 00000041619ffa8c
// Address of the local variable: 00000041619ffacc
// Address of the local variable: 00000041619ffb0c
// Address of the local variable: 00000041619ffb4c // 栈底
//
// 栈顶指针 < 栈底指针,所以栈的增长方向是高地址向低地址增长。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 2.6 二进制文件和文本文件
数据在物理上的存储方式是二进制的,即由0/1字符串构成。而我们解读这些的方式有两种:基于字符编码,和基于值编码。
# 2.6.1 基于字符编码
即每个我们肉眼可读的字符都有唯一对应的0/1字符串,我们读、写这些字符都使用同一套编码方式。
如果某文件的数据使用基于字符的编码,那么该文件即为“文本文件”。
文本文件则在二进制的基础上,进行了字符编码,因此,我们看到的诸如 .txt 以及程序文件都是字符形式。
常见的基于字符的编码有:ASCII码,Unicode编码。
# 2.6.2 基于值编码
可以理解为自定义的编码。
如果某文件的数据使用基于值的编码,那么该文件即为“二进制文件”。不同的应用程序对二进制文件中的每个值会有不同的解读,就像不同的编码对文本文件中的每一/多个字节有不同的解读。
常见的二进制文件有可执行程序、图形、图像、声音等等。
#include <stdio.h>
#include <stddef.h>
#include <assert.h>
int main(int argc, const char* argv[])
{
FILE *fp = fopen("./data.dat", "w+b");
assert(fp != NULL);
int arr[] = {
1,3,5,7,9,11,13,15,17,19
};
if (fwrite(arr, 1, sizeof(arr), fp) != 1) {
if (ferror(fp)) {
perror("error");
}
}
assert(!ferror(fp));
fclose(fp);
fp = fopen("./dat.dat", "w+b");
assert(fp != NULL);
for (size_t i = 0; i < 10; ++ i) {
if (fprintf(fp, "%d", arr[i]) < 0) {
perror("error");
}
}
fclose(fp);
return 0;
}
// 基于字符编码
// $ hexdump -C dat.dat
// 00000000 31 33 35 37 39 31 31 31 33 31 35 31 37 31 39 |135791113151719|
// 0000000f
//
// 基于值编码
// $ hexdump -C data.dat
// 00000000 01 00 00 00 03 00 00 00 05 00 00 00 07 00 00 00 |................|
// 00000010 09 00 00 00 0b 00 00 00 0d 00 00 00 0f 00 00 00 |................|
// 00000020 11 00 00 00 13 00 00 00 |........|
// 00000028
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# 2.7 浮点数的存储
32位下的浮点数存储:
符号位 1 + 指数位(8)+小数位(24)
IEEE754规定, 指数位用于表示[-127, 128]范围内的指数
规定: 在32位单精度类型中, 这个偏移量是127. 在64位双精度类型中, 偏移量是1023. 所以, 这里的偏移量是127。
有了偏移量, 指数位中始终都是一个非负整数。
# 2.8 位域
有些数据在存储时并不需要占用一个完整的字节,只需要占用一个或几个二进制位即可。例如开关只有通电和断电两种状态,用 0 和 1 表示足以,也就是用一个二进位。正是基于这种考虑,C语言又提供了一种叫做位域的数据结构。
在结构体定义时,我们可以指定某个成员变量所占用的二进制位数(Bit),这就是位域。
struct bs{
uint32_t m;
uint32_t n : 4;
uint8_t ch : 6;
};
2
3
4
5
都定义为 unsigned 类型。
位域技术就是在成员变量所占用的内存中选出一部分位宽来存储数据。
C99规定int、unsigned int和 _Bool 可以作为位域类型,但编译器几乎都对此作了扩展。
- 如果一个字节所剩空间不够存放另一位域时,应从下一单元起存放该位域。也可以有意使某位域从下一单元开始。
struct bs
{
unsigned a:4
unsigned :0 /*空域*/
unsigned b:4 /*从下一单元开始存放*/
unsigned c:4
}
2
3
4
5
6
7
空域用 0 填充单元剩下的空间。
- 位域的长度不能大于数据类型本身的长度,比如int类型就能超过32位二进位。
- 位域可以无位域名,这时它只用来作填充或调整位置。无名的位域是不能使用的。
struct k
{
unsigned int a:1
unsigned int :2 /*该2位不能使用*/
unsigned int b:3
unsigned int c:2
};
2
3
4
5
6
7
使用位域的主要目的是压缩存储,其大致规则为:
如果相邻位域字段的类型相同,且其位宽之和小于类型的sizeof大小,则后面的字段将紧邻前一个字段存储,直到不能容纳为止
如果相邻位域字段的类型相同,但其位宽之和大于类型的sizeof大小,则后面的字段将从新的存储单元开始,其偏移量为其类型大小的整数倍;
如果相邻的位域字段的类型不同,则各编译器的具体实现有差异,VC6采取不压缩方式,tdm-gcc,GCC采取压缩方式;
如果位域字段之间穿插着非位域字段,则不进行压缩.
整个结构体的总大小为最宽基本类型成员大小的整数倍。
# 2.9 断言
assert宏的原型定义在assert.h中,其作用是如果它的条件返回错误,则终止程序执行。
assert的作用是现计算表达式 expression ,如果其值为假(即为0),那么它先向 stderr 打印一条出错信息,然后通过调用 abort 来终止程序运行。
通过 NDEBUG 宏关闭,在调试结束后,可以通过在包含 #include 的语句之前插入 #define NDEBUG 来禁用 assert 调用。
gcc -DNDEBUG
assert 的缺点是,频繁调用会极大的影响程序的性能,增加额外的开销。
# 2.9.1 用法总结与注意事项
1. 在函数开始处检验传入参数的合法性
int resetBufferSize(int nNewSize)
{
//功能:改变缓冲区大小,
//参数:nNewSize 缓冲区新长度
//返回值:缓冲区当前长度
//说明:保持原信息内容不变 nNewSize<=0表示清除缓冲区
assert(nNewSize >= 0);
assert(nNewSize <= MAX_BUFFER_SIZE);
...
}
2
3
4
5
6
7
8
9
10
11
12
2. 每个assert只检验一个条件,因为同时检验多个条件时,如果断言失败,无法直观的判断是哪个条件失败
// bad:
assert(nOffset>=0 && nOffset+nSize<=m_nInfomationSize);
// good:
assert(nOffset >= 0);
assert(nOffset+nSize <= m_nInfomationSize);
2
3
4
5
6
7
3. assert和后面的语句应空一行,以形成逻辑和视觉上的一致感
4. 有的地方,assert不能代替条件过滤
程序一般分为Debug 版本和Release 版本,Debug 版本用于内部调试,Release 版本发行给用户使用。 断言assert 是仅在Debug 版本起作用的宏,它用于检查"不应该"发生的情况。以下是一个内存复制程序, 在运行过程中,如果assert 的参数为假,那么程序就会中止。
使用断言的原则:
- 使用断言捕捉不应该发生的非法情况。不要混淆非法情况与错误情况之间的区别,后者是必然存在的并且是一定要作出处理的。
- 使用断言对函数的参数进行确认。
- 在编写函数时,要进行反复的考查,并且自问:"我打算做哪些假定?"一旦确定了的假定,就要使用断言对假定进行检查。
- 一般教科书都鼓励程序员们进行防错性的程序设计,但要记住这种编程风格会隐瞒错误。当进行防错性编程时,如果"不可能发生"的事情的确发生了,则要使用断言进行报警。
# 2.10 变参函数 TODO
TODO: 补充
# 2.11 内存对齐
(1) 性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
(2) 平台原因:不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
(3) 空间原因:没有进行内存对齐的结构体或类会浪费一定的空间,当创建对象越多时,消耗的空间越多。
如果一个变量的内存地址正好位于它长度的整数倍,他就被称做自然对齐。
在设置结构体或类时,不考虑内存对齐问题,会浪费一些空间。
对齐规则:
- struct内部每个成员按自身大小对齐,起始地址是自身宽度的整数倍。
- struct末尾紧贴着一个相同类型的struct,也能够使下一个struct内成员对齐。
- 填充的值为垃圾值,非空。
永远不要用 pragma pack。
#pragma pack(push) // 保存当前的对齐方式
#pragma pack(1)
struct A{
char a;
int b;
short c;
};
#pragma pack(pop)
struct B{
char x;
int y;
short z;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
结构体对齐原则
- 填充的值非空,为垃圾值。
- 按成员中占内存最多的数据类型字节数对齐。
- 每个成员起始位置一定是自己宽度的整数倍。
- 结构体变量占字节数必须是最宽成员数据类型的整数倍。
struct st{
double a; // 8
int16_t b; // 2
int32_t c; // 4
int8_t d; // 1
};
sizeof (struct st) = 8 + 2 + 4 (+2) + 1 (+7) = 24 Bytes.
2
3
4
5
6
7
8
# 2.12 联合体
联合体大小是以所占空间最大的为标准分配空间。
# 2.13 register 存储类型
直接存在 CPU 的寄存器中。
# 2.14 数组指针
对二维数组的定义,第一维的长度是可以缺省的,但是第二维不可缺省。
对数组取地址,指针类型就是数组指针。
int arr[][4] = {0};
int (*p)[4] = arr
# 2.15 数组名和指针的区别
数组名的含义:
- 数组在内存空间的名称。
- 数组的起始地址。
区别一:
- 对数组名取地址得到的是数组所指元素的地址,但类型是数组指针。
- 对指针取地址得到的是指针变量自身的地址。
区别二:
- 数组名是常量指针。
- 指针是变量指针。
区别三:
sizfof(数组名)得到的整个数组的字节数。sizeof(指针)得到的是指针类型的字节数。
指针的访问效率远远高于数组名的访问效率。
对指针进行加法(减法)运算时,它前进(后退)的步长与它指向的数据类型有关。
当数组作为函数的参数进行传递时,该数组自动退化为同类型的指针。
# 2.16 字节序
计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。
但是,人类还是习惯读写大端字节序。所以,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
字节序是由 CPU 决定的。
对于多字节的数据,在内存中存储时,存放字节的顺序为字节序。
大端序
高位放在低地址,低位放在高地址。
小端序。
高位放在高地址,地位放在低地址。
判断字节序:
#include <stdint.h>
#include <stdio.h>
int main(int argc, const char* argv[])
union{
int32_t n;
int8_t ch;
}data;
data.n = 0x00000001;
if(data.ch == 1) {
printf("小端序\n");
else {
printf("大端序\n");
}
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 2.17 位运算取余
位运算适用于除数是 2n
的情况。对 2n
取余,就预示着数字向右移 n 位,这右移的 n 位就是余数。
# 2.18 补码的运算
补码减法运算的公式: [ x -y ] 补= [ x ] 补- [ y ] 补= [ x ] 补+ [ -y ] 补
# 2.19 整型提升
在 K&R 和 C89 的早期实现中,基于 short 和 char 的算术运算陷入两难的困境,因为可能会产生两种不同的结果。因此,在C99中很明确地定义了整型提升的规则. 如果int能够表示原始类型中的所有数值,那么这个数值就被转成int型,否则,它被转成 unsigned int 型。这种规则被称为整型提升。所有其它类型都不会被整型提升改变。
表达式中的字符型和短整型操作数在使用之前被转换为普通类型,这种转换称为整形提升。
char 和 short 在参与运算时,均是先转换为 int 再进行。
通常情况下,在对int类型的数值作运算时,CPU的运算速度是最快的。在x86上,32位算术运算的速度比16位算术运算的速度快一倍。C语言是一个注重效率的语言,所以它会作整型提升,使得程序的运行速度尽可能地快。
# 2.20 _Bool 类型
C99 中,提供了 _Bool 类型,_Bool 只能赋值为 0 或 1,非 0 的值都会被存储为 1。
# 2.21 占位符
%c:字符。%d:十进制整数。%u: 无符号整型%e:使用科学计数法的浮点数,指数部分的e为小写。%E:使用科学计数法的浮点数,指数部分的E为大写。%i:整数,可读取非十进制整数。%f:小数(包含float类型和double类型)。%g:6个有效数字的浮点数。整数部分一旦超过6位,就会自动转为科学计数法,指数部分的e为小写。%G:等同于%g,唯一的区别是指数部分的E为大写。%hd:十进制 short int 类型。%ho:八进制 short int 类型。%hx:十六进制 short int 类型。%hu:unsigned short int 类型。%ld:十进制 long int 类型。%lo:八进制 long int 类型。%lx:十六进制 long int 类型。%lu:unsigned long int 类型。%lld:十进制 long long int 类型。%llo:八进制 long long int 类型。%llx:十六进制 long long int 类型。%llu:unsigned long long int 类型。%Le:科学计数法表示的 long double 类型浮点数。%Lf:long double 类型浮点数。%lf: double%n:已输出的字符串数量。该占位符本身不输出,只将值存储在指定变量之中。%o:八进制整数。%p:指针。%s:字符串。%u:无符号整数(unsigned int)。%x:十六进制整数。%zu:size_t类型。%zd:ssize_t类型。%td: ptrdiff_t 类型。%%:输出一个百分号。%lc:打印宽字符。%ls:打印宽字符串。
%c 和 %hhd 区别:二者针对类型都是单字节整数,也就是char或者unsigned char。不过%c在输入输出的时候,是按照字符操作的。%hhd是按照整数操作。
# 2.22 输出格式控制
-:字段宽度内左对齐。+:显示正负号。#:输出进制前缀。0:填充0,指定宽度内。[num]:指定宽度,超过不截断,少的用空格填充。*:待指定宽度,第一个参数为宽度。.[num]:精度,不够用 0 填充(写入数字最小位数,对于e、f,指定小数位数。对于s,指定输出最大字符数。.*:待指定精度,第一个参数为精度。
# 2.23 size_t
sizeof 操作符的返回结果类型是 size_t,在程序设计的时候,如果处理 size_t ,占位符需要为 %zu,如果是 ssize_t ,则需要用 %zd。
size_t 表示 C 中任何对象所能达到的最大长度。
在声明注入字符数或者数组索引这样的长度变量时用 size_t 是最好的做法,它经常用于循环计数器、数组索引。
如:
for (size_t i = 0; i < 99; ++ i){
...
}
2
3
4
使用 size_t 需包含头文件 <stddef.h>
# 2.24 零长度数组 TODO
又叫做柔性数组,它的主要作用就是为了满足需要变长度的结构体,因此有时也习惯地称为变长数组。
主要用途:变长的报文和字符串处理,为了解决冗余和数组越界问题,和指针相比并不占空间,且不需要二次访存,效率高。
用法:必须在一个结构体的最后,声明一个长度为 0 的数组,就可以使这个结构体是可变长的。
此时长度为 0 的数组并不占用空间,因为数组名本身不占空间,只是一个偏移量,数组名 这个符号本身代表了一个不可修改的地址常量。
例子:
struct line{
struct length;
uint64_t contents[];//uint64_t contents[0]
}
struct line *thisline = malloc(sizeof(struct line) + this_length);
thisline->length = his_length;
enum {
LENGTH = 3
};
typedef struct {
int len;
int value;
int array[];
}SoftArray;
softArray = (SoftArray*) calloc(1, sizeof (SoftArray) + sizeof (int) * LENGTH);
// 销毁时直接 free()
free(softArray);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
struct line 数据结构大小只包含 int 类型的大小,不包含 contents 的大小。
也就是 sizeof(struct line) = sizeof(int)。
网络通信协议: 在网络编程中,柔性数组可以用来表示数据包的可变部分。例如,一个网络通信协议的数据包可能包括一个固定的头部和一个可变长度的数据部分,柔性数组可以用来存储数据部分。
文件格式: 在创建自定义文件格式时,柔性数组可用于表示文件中的可变大小的数据块。这允许您将多个数据块存储在一个文件中,每个数据块的大小可以不同。
数据库系统: 数据库系统中的记录通常具有固定的结构,但有时需要存储可变数量的数据项。柔性数组可以用于在记录中存储可变数量的数据。
解析器和编译器: 在编写解析器或编译器时,柔性数组可用于存储语法树节点或中间代码表示中的可变数量的子节点。
# 2.25 VLA 变长数组
尽量不要使用 VLA,可通过:gcc -Wvla 检测,C++ 不支持。
在 c11 之后是可选的。
可通过宏 __STDC_NO_VLA__ 检测:
#if __STDC_NO_VLA__
#error "不支持 C99 VLA"
#else
...
#endif
2
3
4
5
变长数组的实现默认是通过动态设置栈顶来实现的。
变长数组允许不在栈上,有些编译器可能用 malloc 实现。
VLA目前在 MSVC/GCC 上的实现全部都是利用到了alloca() ,在栈上动态申请一块内存(移动栈指针), 当函数返回时,栈指针回归外一层函数时的状态,因而alloca() 分配的内存得以释放。
实际工程中不推荐使用VLA。原因如下:若数组长度很大,有造成爆栈的危险。OS给进程的栈的大小是有限的。
使用alloca()后会造成部分与栈操作有关的编译器优化失效。因此,若数组长度有可能很大,请直接在堆上分配避免爆栈。
vla 不支持初始化。
C99中对对VLA有一些限制,比如变长数组必须是自动存储类型,也就是说,如果我上面两句放在函数外面就就 不能通过编译了,这是因为在函数外面定义的是全局变量,此外,使用VLA不能对数组进行初始化,因为它的 长度在运行时才能确定。
VLA并不是真正的变长,它实际上只是将数组的长度推迟到运行时确定而已,也就是说C90标准中, 数组的长度必须在编译时期就知道,但C99支持VLA后,数组的长度可以推迟到运行时知道。
# 2.26 关于指针的类型定义
C 语言里,与变量名最近的符号,表明了这个变量的类型,然后一层层向外增加额外的解释。
如
int (*p[10])() 是一个函数指针数组,类型是 int (*[])()。
int (* (*(*pfunc)(int *)) [5])(int *);
分析:
*(*pfunc)(int *)是一个函数指针,参数 int*,返回值是 q 的指针,
分析 int (*q[5])(int *) 的指针,得知 q 是一个函数指针数组,
所以 pfunc 是一个函数指针,接收参数 int*,返回值是 一个函数指针数组的指针,数组的函数指针的类型
是 参数 :int *, 返回值 int。
int (*(*(*pfunc)(int *))[5])(int *);
// 等同于下面的写法:
typedef int (*f)(int *); // f 是函数指针
typedef f (*g)[5]; // g 是数组指针,数组类型是 f
typedef g (*h)(int *); // h 是函数指针,返回值是数组指针
// 强制类型转换,将 0 强制转换为一个函数指针。
(*(void(*)())0)();
2
3
4
5
6
7
8
9
10
# 2.27 目录结构
src项目源代码和编译它的 Makefile 文件。- Makefile
incl存放头文件。bin存放可执行程序。lib存放库文件。etc存放配置文件。static静态库源文件和编译它的 Makefile文件。- Makefile
dynamic动态库源文件和编译它的 Makefile 文件。- Makefile
docs项目文档。obj存放目标文件和 Makefile 文件。- Makefile
- Makefile
# 2.28 static inline
inline 是基于实现的关键字。
inline是c99的特性。在c99中,inline是向编译器建议,将被inline修饰的函数以内联的方式嵌入到调用这个函数的地方。而编译器会判断这样做是否合适,以此最终决定是否这么做。
开发者决定不了一个函数是否被内联,开发者只有建议权,只有编译器具有决定权。
多数情况下,inline 前面会加static关键字。why?
分开理解:
static 意味着本地化,每个包含头文件的C文件均在本地产生一个独立的内联函数。当有多个C文件包含头文件时,不会因为函数名相同而报重定义错误。(代价就是代码所占的空间会变大)
inline意味着建议内联,至于能否真正内联,看编译器。
因为内联函数要在调用点展开,所以编译器必须随处可见内联函数的定义,要不然就成了非内联函数的调用了。所以,这要求每个调用了内联函数的文件都出现了该内联函数的定义。
因此,将内联函数的定义放在头文件里实现是合适的,省却你为每个文件实现一次的麻烦。
声明跟定义要一致:如果在每个文件里都实现一次该内联函数的话,那么,最好保证每个定义都是一样的,否则,将会引起未定义的行为。如果不是每个文件里的定义都一样,那么,编译器展开的是哪一个,那要看具体的编译器而定。所以,最好将内联函数定义放在头文件中。
C++ 中,定义在类中的成员函数默认都是内联的,如果在类定义时就在类内给出函数定义,那当然最好。
以下情况不宜使用内联: (1)如果函数体内的代码比较长,使用内联将导致内存消耗代价较高。 (2)如果函数体内出现循环,那么执行函数体内代码的时间要比函数调用的开销大。类的构造函数和析构函数容易让人误解成使用内联更有效。要当心构造函数和析构函数可能会隐藏一些行为,如"偷偷地"执行了基类或成员对象的构造函数和析构函数。所以不要随便地将构造函数和析构函数的定义体放在类声明中。一个好的编译器将会根据函数的定义体,自动地取消不值得的内联(这进一步说明了 inline 不应该出现在函数的声明中)。
# 2.29 枚举和宏的区别
宏在预处理阶段将名字替换成对应的值,枚举在编译阶段将名字替换成对应的值。
我们可以将枚举理解为编译阶段的宏。
枚举用于定义一组具有名称的整数常量。
宏只是单纯的替换。
const 是个类型限定符,用于声明一个只读变量,提供类型安全。
# 2.30 C 语言存储类
C 语言提供了几种存储类型,用于描述变量在内存中的存储方式和生命周期。以下是 C 语言中常见的存储类型:
自动存储类(auto):这是默认的存储类,用于描述在函数内部声明的局部变量。自动变量的生命周期与其所在的函数调用周期相对应。它们在函数调用时被创建,在函数返回时被销毁。
静态存储类(static):静态存储类用于描述具有静态生命周期的变量。静态变量在程序运行期间一直存在,不受函数调用的影响。静态变量在声明时被初始化,并且只在首次进入声明它的作用域时进行初始化。
寄存器存储类(register):寄存器存储类用于请求编译器将变量存储在寄存器中,以便快速访问。这只是一种建议,编译器可以忽略它。使用寄存器存储类的变量不能获取其地址,因为它们可能没有分配内存。
外部存储类(extern):外部存储类用于描述全局变量或跨文件共享的变量。它们在整个程序的执行期间都存在,并可以被其他文件访问。
int arr[3];
extern int arr[];
2
静态线程存储类(thread_local):静态线程存储类用于描述线程本地存储的变量。每个线程都拥有其自己的变量实例,并且在线程生命周期内保持状态,线程开始时分配,线程结束时销毁。
这些存储类可以与变量声明一起使用,以指定变量的存储类型和生命周期。具体使用哪种存储类取决于变量的需求和上下文。
C++ 中还有 mutable 存储类,仅适用于类成员变量。以mutable修饰的成员变量可以在const成员函数中修改。
_Thread_local 关键词只对声明于命名空间作用域的对象、声明于块作用域的对象及静态数据成员允许。它指示对象拥有线程存储期。它能与 static 或 extern 结合,以分别指定内部或外部链接(除了静态数据成员始终拥有外部链接),但附加的 static 不影响存储期。
线程存储期: 对象的存储在线程开始时分配,而在线程结束时解分配。每个线程拥有其自身的对象实例。唯有声明为 thread_local 的对象拥有此存储期。 thread_local 能与 static 或 extern 一同出现,以调整链接。
static thread_local 和 thread_local 声明是等价的,都是指定变量的周期是在线程内部,并且是静态的。
# 2.31 标准预定义宏
编译器支持 ISO C99、C11、C17 和 ISO C++17 标准指定的以下预定义宏:
__cplusplus:当翻译单元编译为 C++ 时,定义为整数文本值。 其他情况下则不定义。__DATE__:当前源文件的编译日期。 日期是 Mmm dd yyyy 格式的恒定长度字符串文本 。 月份名 Mmm 与 C 运行时库 (CRT) asctime 函数生成的缩写月份名相同 。 如果值小于 10,则日期 dd 的第一个字符为空格 。 任何情况下都会定义此宏。__FILE__:当前源文件的名称。__FILE__展开为字符型字符串文本。 要确保显示文件的完整路径,请使用 /FC(诊断中源代码文件的完整路径)。 任何情况下都会定义此宏。__LINE__:定义为当前源文件中的整数行号。 可使用 #line 指令来更改__LINE__宏的值。__LINE__值的整型类型因上下文而异。 任何情况下都会定义此宏。__STDC__:仅在编译为 C,并且指定了 /Za 编译器选项时,定义为 1。 从 Visual Studio 2022 17.2 版本开始,当编译为 C 并指定 /std:c11 或 /std:c17 编译器选项时,它也定义为 1。 其他情况下则不定义。__STDC_HOSTED__:如果实现是托管实现并且支持整个必需的标准库,则定义为 1 。 其他情况下则定义为 0。__STDC_NO_ATOMICS__如果实现不支持可选的标准原子,则定义为 1。 当编译为 C 且指定 /std C11 或 C17 选项之一时,MSVC 实现会将其定义为 1。__STDC_NO_COMPLEX__如果实现不支持可选的标准复数,则定义为 1。 当编译为 C 且指定 /std C11 或 C17 选项之一时,MSVC 实现会将其定义为 1。__STDC_NO_THREADS__如果实现不支持可选的标准线程,则定义为 1。 当编译为 C 且指定 /std C11 或 C17 选项之一时,MSVC 实现会将其定义为 1。__STDC_NO_VLA__如果实现不支持可选的可变长度数组,则定义为 1。 当编译为 C 且指定 /std C11 或 C17 选项之一时,MSVC 实现会将其定义为 1。__STDC_VERSION__当编译为 C 且指定 /std C11 或 C17 选项之一时定义。 对于 /std:c11,它扩展到 201112L;对于 /std:c17,则扩展到 201710L。__STDCPP_DEFAULT_NEW_ALIGNMENT__当指定 /std:c17 或更高版本时,此宏会扩展为 size_t 字面量,该字面量的对齐值由对非对齐感知的 operator new 的调用所保证。 较大的对齐值传递到对齐感知重载,例如 operator new(std::size_t, std::align_val_t)。 有关详细信息,请参阅 /Zc:alignedNew(C++17 过度对齐的分配)。__STDCPP_THREADS__:当且仅当程序可以有多个执行线程并编译为 C++ 时,定义为 1。 其他情况下则不定义。__TIME__:预处理翻译单元的翻译时间。 时间是 hh:mm:ss 格式的字符型字符串文本,与 CRT asctime 函数返回的时间相同 。 任何情况下都会定义此宏。__STDC_ANALYZABLE__限制某些未定义行为潜在执行结果,提升程序的静态语法分析结果。
# 函数名和函数地址
函数名可以当函数地址用,但是函数名并不是函数的地址,类型不同。
# const
c语言中const全局变量存储在只读数据段,编译期最初将其保存在符号表中,第一次使用时为其分配内存,在程序结束时释放,不能通过取地址修改。
而const局部变量(局部变量就是在函数中定义的一个const变量,)存储在栈中,代码块结束时释放,可以通过指针修改。
C 中,一个 const 变量总是需要一块内存空间,const 全局变量默认为外部链接。
← 1 简易 C 语言编程规范 3 c 问题集 →